
The TL;DR
E-Learning has been very widespread in the past century due to the rise of computers. Several benefits of e-learning include reduced costs, scalability, consistency and the ability to accommodate different time zones. However, there are skeptics who say that e-learning can be a “bane” as it removes the focus of the students due to the freedom it gives. In this exercise, we discover knowledge on a dataset where students use an e-learning facility wherein while using the platform, their online footprint is being recorded. From these, we engineered four features: (1) focus_level — times where they were browsing non-related sites, (2) time_finished — time it takes to finish the exercise, (3) idle_time — time where they were doing nothing, and (4) activity_level — number of clicks, keystrokes and mouse wheeling they made. We then find correlation of these engineered features with grades, using a linear model. It was found that among all of the features, only the time_finished was the significant variable and the model with only this variable gives the best prediction. This means that the faster a student finishes the exercise, the higher the student's final grade will be. Among all the variables, this is the most unrelated to e-learning. This also means that a student browsing non-related sites, with lots of idle time and with little activity level does not necessarily get lower grades. As such, while e-learning may remove the focus of the students as they are free to visit any site during the session, it does not necessarily mean that e-learning will be a “bane”, as it does not significantly affect the student's grade.
The Actual Analysis
After checking the data, we can formulate what we may want to discover. From the grades data, we can see that there are students that have very low marks. What we want to ask is if this is due to the fact that they are just doing nothing or are doing other things on the computer. We would also like to know if more activity on the computer means higher grades. As such we would like to engineer these features, with grades as our response variable:
- focus — Is the student viewing pages related to the exercise? Here, we would just like to classify everything as related or non-related.
- idle_time — How much idle time was spent by the student?
- time_finished — How long did the student take to finish? We will find the difference of the start time and the end time.
- activity_level — Did the student have more activity (keystrokes, mouse movements)?
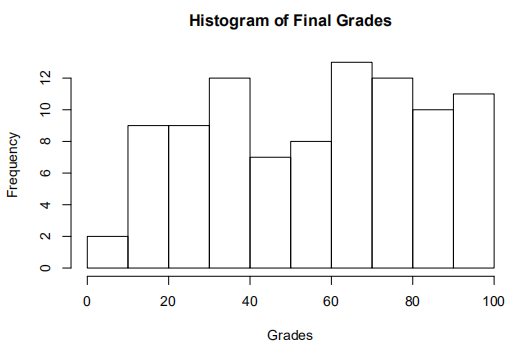
We will consolidate this into just one feature. We check the histogram of the final grades: from here, we can see the almost uniform distribution of the grades from 10–100. We now engineer the other variables, using only the students with grades. We check the correlation of our new variables.
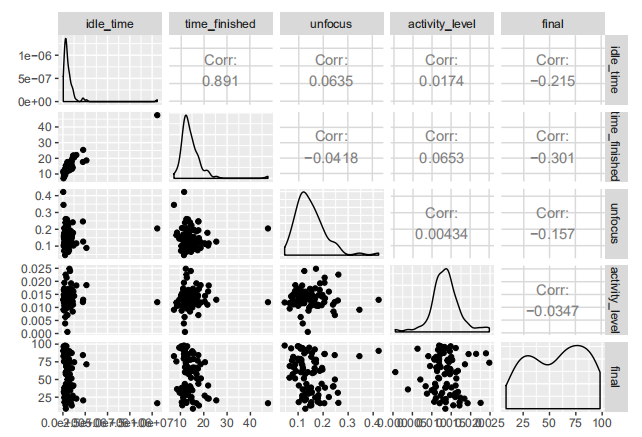
Comparing the correlation of final variables with all other engineered features, we can see strong correlation with idle_time and time_finished.
Here is our final formula:
lm(formula = final ~ time_finished, data = education_train)It means that only the time finished affects the final grade. If a student passes their worksheet earlier, the higher their grade is. The full code of this blog can be seen at github.com/rlbartolome/education. Here, I discussed how the data is transformed and how I did the linear model selection!
← All Machine Learning articles