
Advertisements have always been an essential part of all businesses around the world. In particular, internet advertisements in the form of banners in websites have been on the rise especially at the turn of the century. However, many users do not want to be cluttered with these images.
In this exercise, we explore a dataset where we have several image features, such as size, if the site is local and on what site it came from. Exploring the dataset, we found that it had a lot of components (1,559 variables). As such, we performed Principal Components Analysis (PCA) to the data to decrease the number of components. We found that (1) 110 components can explain 75% of the variance and (2) 73 components can explain 60% of the variance, which is a massive decrease from the original number of components. We also classified the images using Support Vector Machines, where indeed, we found that it is possible to classify images as ads or non-ads with an accuracy of 96.2% using a Linear Kernel. This is similar to what the original authors got at 97% accuracy.
From the source, it was described that this dataset represents a set of possible advertisements on Internet pages. The features encode the geometry of the image as well as phrases occurring in the URL, the image's URL and alt text, the anchor text, and words occurring near the anchor text. The task is to predict whether an image is an advertisement (“ad”) or not (“nonad”). The following is the data attributes given by the original creators of the dataset:
- height: continuous
- width: continuous
- aratio: continuous
- local: 0,1.
- 457 features from url terms, each of the form “url*term1+term2…”
- 495 features from origurl terms, in same form
- 472 features from ancurl terms, in same form
- 111 features from alt terms, in same form
- 19 features from caption terms
- tagging if the image is an ad or a non-ad
Principal Components Analysis
We can see that our data is 3,278 entries with 1,559 columns. Our data has too many columns. To solve this too much dimensionality, we shall use principal components analysis. We run an initial PCA fit on the full data set.
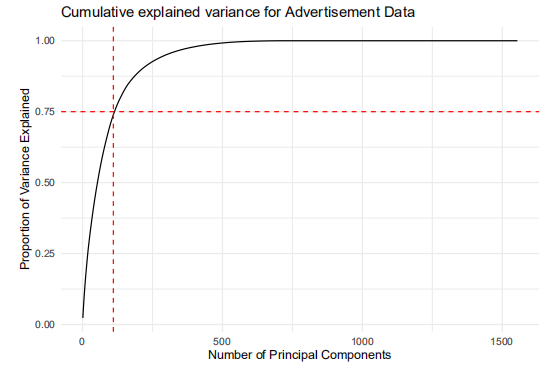
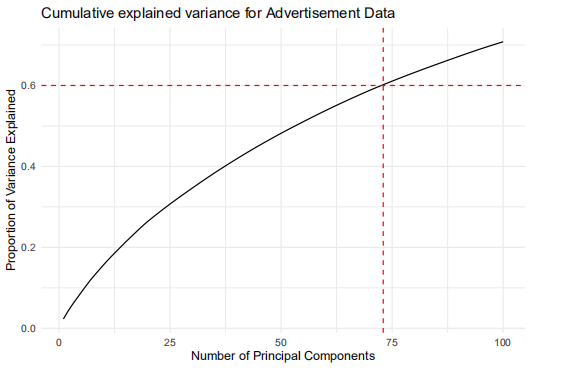
We find that up to ~110 components, we achieve around 75% of the cumulative proportion of variance explained. We try to lower it since 110 components is still very large: at 73 components, we can explain 60% of the variance.
Support Vector Machines
We try Support Vector Machines to predict if an image is an ad or not. We split the data into train and test sets, and find the best model.
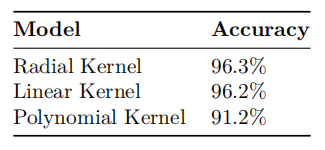
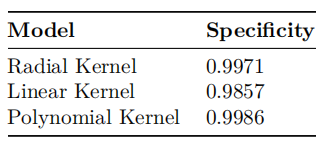
We check the best model in terms of the accuracy. For the SVM technique, we can see that the best model in terms of accuracy is the SVM model with a Linear kernel, having 96.3% accuracy. However, this is a close call with the one with a Radial Kernel. Now, we look at the value of specificity: the Radial Kernel has a better specificity. As such, since the accuracy difference between the Radial and Linear kernels is very small, we would choose the Linear Kernel SVM to classify ads based on the attributes provided.
The full code can be found at github.com/rlbartolome/advertisement. I included the data loading, transformation and kernel selection codes there.